I’ve recently had a chance to benchmark GAIA in Google cloud. The goal was to test how quickly I can process compressed text data (i.e read and uncompress on the fly) when running on a single VM and reading directly from cloud storage. The results were quite surprising.
In order to focus on I/O read only and eliminate potential bottlenecks related to local disks, I’ve written a simple benchmark program mr_read_test using GAIA-MR.
class NoOpMapper {
public:
void Do(string val, mr3::DoContext<string>* context) {} //! Does not output any data.
};
...
std::vector<string> inputs;
for (int i = 1; i < argc; ++i) {
inputs.push_back(argv[i]);
}
StringTable ss = pipeline->ReadText("inp1", inputs);
StringTable out_table = ss.Map<NoOpMapper>("map"); //! Map with noop mapper.
out_table.Write("outp1", pb::WireFormat::TXT)
.WithModNSharding(10, [](const string& s) { return 0; })
.AndCompress(pb::Output::ZSTD, 1);
pipeline->Run(runner);
Setup
I’ve used 32 core machine on Google Cloud. The documentation says that Google does not cap ingress traffic but we can roughly assume to expect around 10Gbit/s or 1.25GB/s. I did not find any references to Google storage bandwidth caps. I was curious to know if I can reach 1.25GB/s cap by reading compressed data and uncompress it on the fly. Storing compressed data in the cloud is a good CPU vs I/O tradeoff because usually, in the cloud, we are bottlenecked on I/O bandwidth. I’ve prepared 2TB dataset comprised of 260 thousand zstd compressed files of different sizes that should inflict enough load on the framework.
I’ve used zstd compression because it’s the best open source compressor that exists these days. If you did not use it before - do try it. It’s especially efficient during the decompression phase, reaching very high speeds. By the way, GAIA-MR supports both gzip and zstd formats out of the box.
By default, the framework creates a 2 IO read fibers per each CPU core.
For 32 core instance, it means that the framework creates
64 socket connections to google storage api gateway (In general, you can control
this setting with --map_io_read_factor flag).
I’ve used slightly modified ubuntu 18.04 image provided by Google cloud.
Benchmark
To run mr_read_test I used the following command:
/usr/bin/time -v mr_read_test --map_io_read_factor=2 gs://mytestbucket/mydataset/**
I’ve used double star suffix to instruct the framework to treat the path as glob and expand it recursively.
Results
The time command exited with the following statistics:
Command being timed: "mr_read_test --map_io_read_factor=2 gs://mytestbucket/mydataset/**"
User time (seconds): 38352.26
System time (seconds): 1625.60
Percent of CPU this job got: 2137%
Elapsed (wall clock) time (h:mm:ss or m:ss): 31:10.32
Maximum resident set size (kbytes): 231720
Major (requiring I/O) page faults: 129
Minor (reclaiming a frame) page faults: 104884
Voluntary context switches: 19396238
Involuntary context switches: 13937163
File system inputs: 76840
File system outputs: 102280
Page size (bytes): 4096
Exit status: 0
This htop snapshot 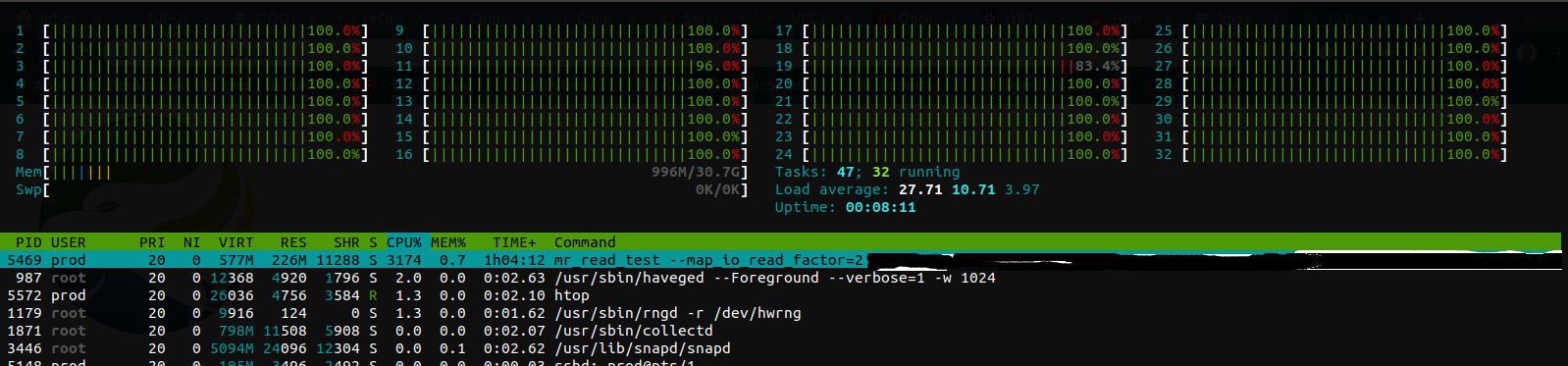 shows that we succeeded
to utilize all 32 cores fully. Moreover all-green bars show that CPUs spend most of their
time in a user land.
shows that we succeeded
to utilize all 32 cores fully. Moreover all-green bars show that CPUs spend most of their
time in a user land.
What can we say about our goal of reading compressed data quickly? So, first of all, just dividing 2TB by total 31:10 minutes gives us 1.07GB/s of reading the compressed data. It’s not bad, I guess since we also included the bootstrapping time where the framework expands the input path into 260K file objects.
But if we look on the network usage 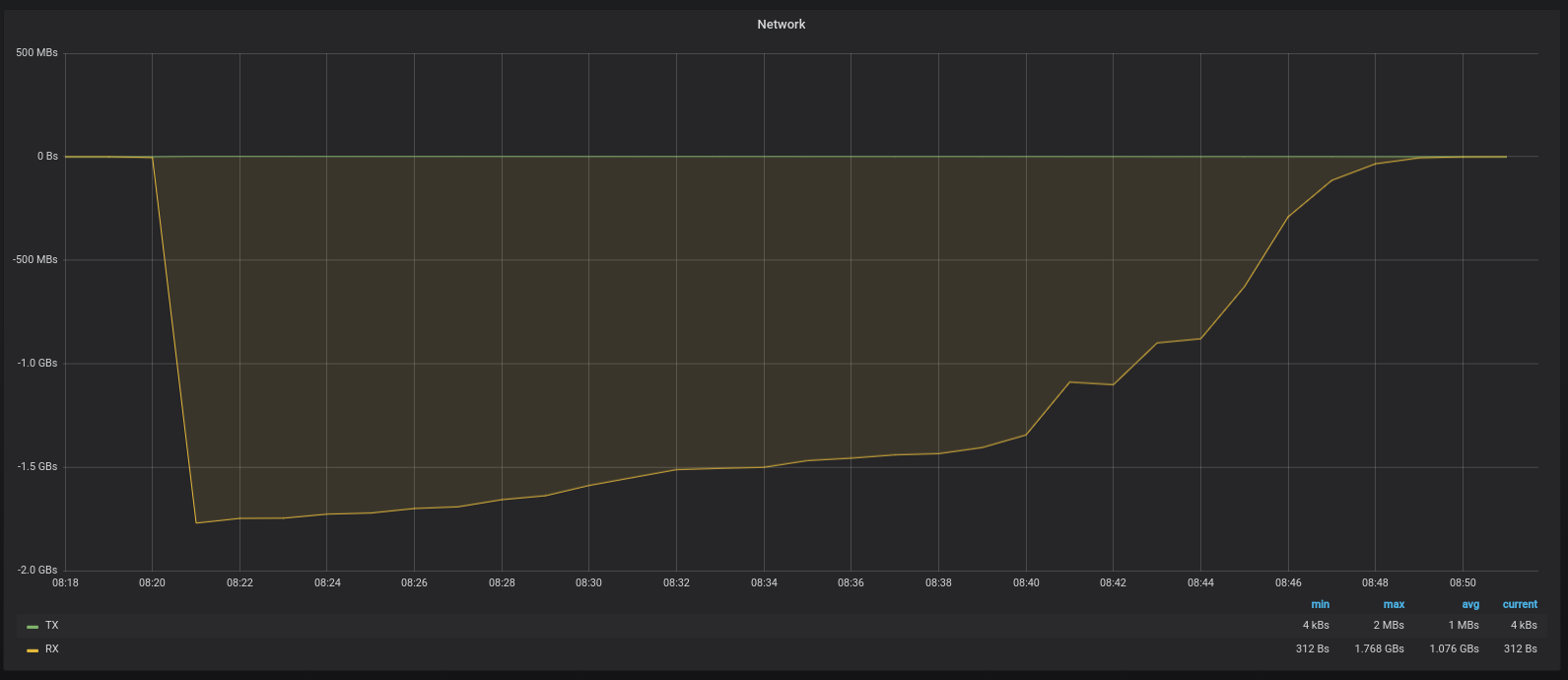 we can see
that we reached 1.76GB/s at peak. It’s above the expected 1.25GB speed.
we can see
that we reached 1.76GB/s at peak. It’s above the expected 1.25GB speed.
Summary
I’ve shown that GAIA-MR can read efficiently datasets of order of few terabytes of compressed data on a single node. Just by using 64 parallel connections to Google storage gateway we’ve reached 1.76GB/s peak speed and were bottlenecked on CPU. Google cloud network and GCS provided me with the bandwidth I would not expect to reach with disk based systems. I think that GAIA-MR in a cloud environment can provide very good value for money when batch processing datasets of few terrabytes. Please try it and tell me what you think!