There are many Java-based mapreduce frameworks that exist today - Apache Beam, Flink, Apex are to name few.
GAIA-MR is my attempt to show advantages of a C++ over other languages in this domain. It’s currently implemented for a single machine but even with this restriction I’ve seen up-to 3-7 times reduction in cost and running time vs current alternatives.
Please note that the single machine restriction put a hard limit on how much data we can process, nethertheless GAIA-MR shines with small-to-medium size workloads (~1TB). This part gives an introduction about mapreduce in general.
Background
Before I start explaining about GAIA, I would like to explain what MapReduce is for. Originally, it was introduced by Google and then was quickly picked up by the industry and rebranded externally as Hadoop.
A mapreduce algorithm is a glorified GroupBy or HashJoin operation from the DB world.
Its purpose is to go over (big) data (I hate this term!) and transform it in such a way that pieces of information dispersed across different sources could be grouped for further processing.
One of the big advantages of Mapreduce framework is that it allows clean separation between low-level mechanics like multi-threading, multi-machine communication, disk-based algorithms, external data structures, efficient I/O optimization, etc - on the one side, and user-provided pipeline logic on the other side. Another advantage is virtualization of resources that allows the framework to run over multiple CPUs, multiple disks and machines in a way that is semi-transparent to a user.
In other words, a user may focus on his high-level processing task. All this of course as long as his algorithm can be modeled with one or more MapReduce steps.
Mapreduce Step
A mapreduce step is essentially combined from 2 operators: a mapper and a reducer. Mappers go over 1 or more different input sources comprised of mutually independent records. A mapper reads each record, applies user-supplied data transformation, possibly filters out or extends records with more data and then partitions its output according to some rule. Mappers can multiply the amount of incoming data by some factor or reduce it to almost nothing. The main restriction they have is that mappers do not control which records exactly they are gonna process and they should not assume how many mapper processors will run. They run independently from each other and usually do not pass information between them.
See 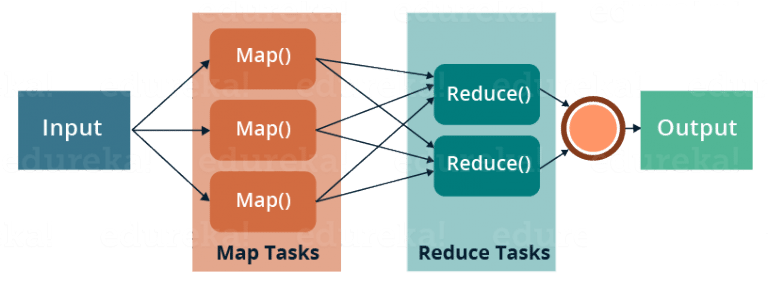
Reducers, on the other hand, read already partitioned data. The data is essentially grouped together according to user-supplied criteria into multiple groups, or as we call them “shards”. Usually those “shards” can be loaded fully into RAM.
Suppose, for example, WalMart wants to join last 10 years of its buyer transactions with another dataset of their buyers personal details. Both sources should be joined by user id but unfortunately they can not be loaded into RAM due to their huge size. Not to worry - Mapreduce to the rescue!
We can provide a mapper that just output records from each dataset into
intermediate shards using user_id % N rule. Thus we produce N shards for each dataset.
The mapreduce will colocate information about each user in a single shard per source
at the end of the mapping phase using the sharding function user_id % N.
N must be large enough to allow loading of each shard into workers memory.
The mapping step of moving randomly distributed records from the input dataset to partitioned one
allows us performing the next step.
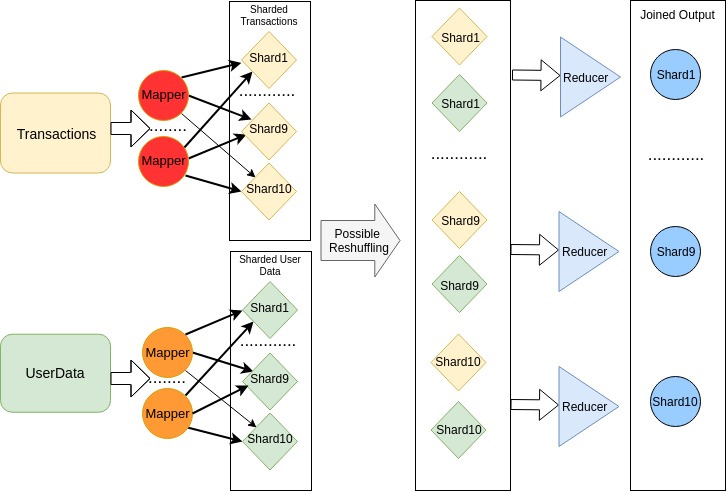
Reducer processors load shards Transaction'(i) and UserData'(i) into RAM. Those shards produced by mappers and they contain all the records for which user_id % N = i. After loading those shards, reducers can join them using hash-join
or merge sort algorithms. Eventually, reducers produce N output shards that contain the joined information.
See the picture above. Therefore, sharding allows reducing the size of the minimal working set
to one that can fit into RAM.
Classic mapreduce flow and the API
Usually a framework is configured by providing instantiations of mapper or reducer classes.
For example, a mapper class may look like this:
class Mapper {
public:
void Map(RecordType input, Context<OutputType>* context);
...
};
It might have a function void Map(RecordType input, Context<OutputType>* context)
that is implemented by pipeline developer. This function should contain pipeline specific logic
and it can call context->Write(shard_id, joined_key, map_output) any number of times.
The framework instantiates mapper classes on multiple machines processes, passes input data to them,
stores intermediate shards produced by mappers and finally sorts and partitions them.
After all the framework instantiates reducer classes. A reducer class might look like this:
class Reducer {
public:
void Reduce(KeyType key, Stream<ValueType>& stream, Writer<OutputType>* writer);
...
};
Reduce API
Reduce will be called with joined key and a stream of values corresponding to that key.
In our walmart example, the key would be user_id and Stream<ValueType> will contain all
the transactions for that user and his own user data from the second dataset.
Each key will be sent to exactly one reducer that processes its shard.
Reduce will be called by the framework for each key and will be able to output
its final result via Writer. Reducers and Mappers do not talk with each other and usually behave
like independent entities.
A classic Reducer interface guarantees to provide us each key with its values grouped.
In order to do this, the mapreduce framework is usually required to shuffle and sort the intermediate shards before
applying reducers on them. Therefore, having values colocated together with their keys requires additional I/O:
we need to load each shard, sort it and write again. This way we will be able to keep file iterators per each
sorted shard and reduce on them with O(N) complexity by just seeking over the files.
GAIA MR
GAIA-MR provides weaker guarantees than most of modern MR frameworks today: it provides shard-level abstraction by moving the responsibility for row level functionality back to the developer.
By weakening its guarantees, GAIA-MR succeeds to reduce redundant I/O for many use-cases. As a result, instead of implementing merge-sort in the framework, GAIA-MR allows a user to perform hash-join in its user code. Using modern, cache friendly data structures provided together with GAIA framework, a user can implement hash-table join with just few lines of code. Instead of trusting the generic framework on how to do optimizations, I trust a developer to fit his code to specific problem he is trying to solve. In the next post I will go-over the concrete example and show how we can write a mapreduce pipeline in GAIA-MR.
In addition, its thread-per-core, horizontally scalable architecture allow loading machines of any size thus adapting hardware configuration to pipeline size and complexity. This is especially useful for cloud environments where you can relatively easily setup a machine for your needs.